
A lot has been written about impact factors, and why they are a poor indicator of article quality (just google it). Even for the one thing that the impact factor is meant to measure, ie, future citations, it performs badly. There are now many empirical studies on this. Sadly, in 2016, scientists in hiring or promotion committees still value impact factors very highly, especially in life sciences. Yes, in a domain of science that is meant to be highly empirical, scientists still prefer to look away from compelling evidence that impact factors should not be used for evaluating research. Recently, in a PhD thesis committee, we were discussing the grade and one member, an experimental biologist, raised the issue that the candidate had not published in the highest ranked journals. We opposed that we were there precisely to evaluate the manuscript itself as a whole, not some elements of CV. He admitted later that he had not read the thesis.
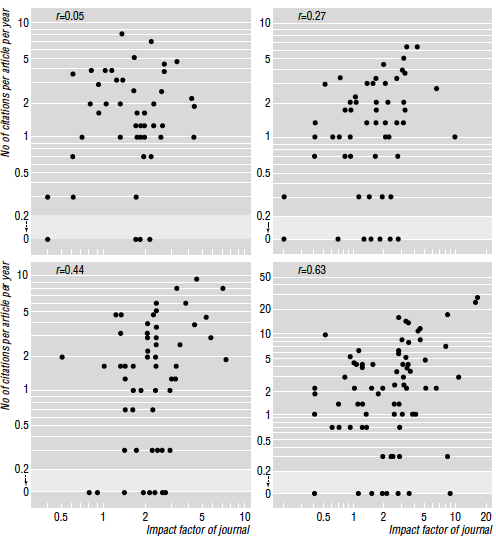
I could simply cite the overwhelming evidence. But I want to make a simpler point of statistics. Many things are wrong with using impact factors, but let us just consider the one thing it is meant for, ie, predicting the number of future citations of papers. We know that for any journal, the distributions of citations is very broad and highly skewed. According to Seglen (1997), “articles in the most cited half of articles in a journal are cited 10 times as often as the least cited half”. In practice, if you are given the name of the journal in which a paper has been published, you will not know its future number of citations. From a purely statistical point of view, journal name is just not very significant.
Examples are sometimes more convincing that hard facts. So from the paper I just cited, number of citations vs. impact factor for all publications of 4 scientists:
Now look at my own publication statistics. To be more rigorous, I should calculate the citations per year, but the point is obvious enough. My top 3 cited papers were published in: J. Neurophys (IF 2.8); J. Comp. Neuro (IF 1.8); Frontiers in Neuroinformatics(IF 1.3). This third paper (on the Brian simulator) was published in 2008, and the same year I had a paper in Neuron, which has gathered about 4 times fewer citations. And this is in spite of the fact that papers published in big journals are obviously much more visible (ie there is an expected boost in citations that is unrelated to article quality).
Is this really surprising? In a big journal, just like in a small journal, decisions are based on n = 2 or 3 reviewers, selected by one editor, i.e. a biased sample of size 2/3; just after an editorial selection based on n = 1 editor, in many cases not a professional scientist.
It’s 2016 and life scientists have been recently warned repeatedly that good statistics require large unbiased samples, but impact factors, totally insignificant pieces of information, are still broadly used to distribute grants and make careers. So yes, using impact factors as a proxy to evaluate the quality of papers or of their authors is a display of poor scientific practice.
To me the problem with this is so not much that bad decisions are being made, but that it has a huge influence on the way science is done. Scientists know that they are being evaluated in this way, and this influences their research (especially for students and postdocs) so that it meets the editorial biases of the big journals. In 1952, Hodgkin and Huxley published 120 pages in Journal of Physiology, basically defining the field of electrophysiology. Who would take the risk of doing this today at the age of 35, instead of a career-making 4-page Nature paper?
Totally agree. But evaluating science well is not exactly the same thing as being a good scientist (although this may be part of it). So a more adequate title might be "You don't evaluate science properly if..." or "You are not a good scientific evaluator if...".
My point was that it shows a level of statistical incompetence that is incompatible with doing good science.
Ping : February 2017 | Brette's free journal of theoretical neuroscience